A Text Encoding Pi
Recently I particpated in another CTF. This time it was TSG CTF, and despite finding it very difficult it was still a good experience.
I devoted most of my time during this CTF to the Misc challenge marked 'Beginner's Misc'. Although I had a brief look at some other problems this is the only one I was able to solve in the end, along with some help from my friend.
The Problem
The problem seemed pretty easy at first glance honestly. They gave the code for the application running on the server, and the goal became clear quite quickly. Here is the code:
from base64 import b64encode
import math
exploit = input('? ')
if eval(b64encode(exploit.encode('UTF-8'))) == math.pi:
print(open('flag.txt').read())
Okay, so the application takes our input UTF-8 encodes it and then base64 encodes it, then executes it. I began this problem by working backwards figuring that, our end result is a base64 string being evaluated needs to return a value that equals `math.pi`.
I got up the base64 page and pretty quickly worked out what sort of payload we need. Base64 consists of a-Z, 0-9 as well as characters '/', '+' and '=' (though equals is only for padding).
Honestly at this stage I thought I had solved the problem (especially as it is marked as beginner) so I thought all I need to do is get the base64 string: "3+141592653589793/1000000000000000" as our code to eventually be executed. Little did I know that this challenge was just beginning.
I wrote the following code, expecting to be done with this challenge immediately:
import base64
base_bytes = base64.b64decode("3+141592653589793/1000000000000000")
print(base_bytes.decode())
I figured the bytes then needed to be decoded to UTF-8 so that they could be parsed by the server and we'd be good to go. Unfortunately I was soon greeted by an unfortunate error:
"binascii.Error: Incorrect padding"
No matter I thought, I'll just pad with leading zeros on the 3. Like so: "003+14... etc."
Unfortunately this lead to the new, and less easily overcome error:
"UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte"
Now the challenge had really begun.
UTF-8 and base64 at War
While the bytes I generared in the code above, would certainly equal my desired string when base64 encoded, the trick lies in the fact that not all sequences of bytes are valid UTF-8 as the Wikipedia page suggests. And the error given above about 'invalid continuation byte' refers to the sequences in the table below:
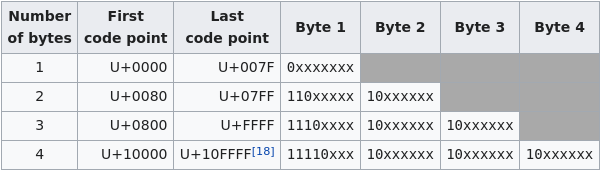
Another trick here, is that base64, aiming to be a dense format for information encodes it's characters in 6 bits, which makes things super confusing. In order to provide some clarity I have also provided the base64 character table below, as I spent the rest of the day staring at these two tables and fiddling with numbers:
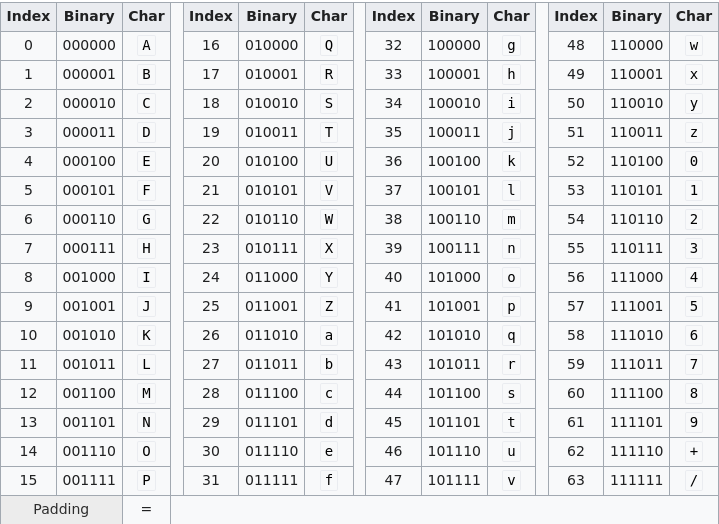
Okay, so what are our options, the most attractive option in the UTF-8 table is the 3-byte sequence. The reason for this being that 3-bytes = 24bits and this divides evenly into the base64 characters length (if you recall from earlier - is 6 bits) so we can be more consistent with the format of the bytes and their correspondence to characters in our result.
Okay, if you are still with me, well done, as that's the most confusing bit out of the way. Now let's dive into how to construct a number vaguely resembling pi from these unique constraints.
Baking a Pi
If we use the tables above, and decide to stick to 3-byte UTF-8 sequences for simplicity's sake, we see that our 3-byte sequence can begin with any digit between 4 and 7. It must be then be followed by a digit, again between 4 and 7 (note the '10' bit sequence in position 3 and 4 necessary to make a valid UTF-8 seqeunce). Then the next number must be either '2' or '6' (though hypothetically this could be a plus, it makes things a bit trickier, so I decided to ignore this possibility). This is due to the '10' sequence needing to be now in the 5th and 6th bits of the base64 character. The good news with the 3-byte sequence is that the last 6 bits are free, so we can do any character there, though in reality most of the time we want either '+' or '/' for reasons that I hope will soon become clear.
Okay, so technicalities out of the way, what does this mean our string needs to look like? Something like this is what's required:
776/776+776/776+776/776
The especially astute amongst you may have noticed here that these values, conforming to the pattern described above, is also equal to 3. This is a great start, and in fact what was used in the eventual payload, but we are going to have to do a lot better. Because although 3 is pretty close to pi, it is this last fractional part where the real difficulty lies.
One more thing to note quickly before we move on is the fact that the sequence I gave as an example above would not be valid, as it's padding is slightly wrong. Most of the numbers we use are 3-digits, because it is easier then to divide and add the parts needed to make up pi, but the final 3-byte seqeunce needs one additional character in order to be valid base64 and not need '=' padding, as this would cause the input to not be evaluated correctly. We will solve this problem in the next step, but I wont' go into detail about this.
Precision
I started out doing some experimenting in the python REPL to see if I could get relatively close to pi, before using some brute-force to work out the remaining portion. I came up with many possible combinations, but the best I found intially was:
>>> 776/776+776/776+776/776+6429776/45494422
3.1413310845008646
As you can see this is starting to take shape, though if we look in the REPL at math.pi's value to determine the precision needed we get:
>>> math.pi
3.141592653589793
To get this level of precision we can abuse the fact that we can use the same sort of number format desribed above to create some tiny fractions. Taking 442/(some large number) we can multiply this many times over to align the last few decimal places to python's math.pi value.
In the end my UTF-8 encoded string was >300kb which is kind of ridiculous but it gets the job done. With our pi file we can now run:
$ cat exploit | nc
And back came the flag!
This was a very unusual, but highly enjoyable challenge, in the process I learnt a lot about UTF-8 as well as base64. There was a lot of trial and error involved but it was a huge relief to get this flag in the end. One more note, I could not have completed this challenge without help from my friend Andy. He came up with the idea for utilising the 3-byte sequences for easier patterns in the exploit text. And in fact he completed this challenge before I did, though we used a similar method to get there, his code was cleaner and made it a bit easier to get to the end product. So big kudos there, and thanks for the help.
- etopiei (19/07/2020)